2020. 4. 9. 20:54ㆍ알고리즘/이론
목차
1. Prim 알고리즘의 개념
2. Prim 알고리즘의 구현
3. Kruskal 알고리즘과 Prim 알고리즘의 비교
이전 포스팅에서는 최소 신장 트리를 만들기 위한 알고리즘으로 Kruskal 알고리즘에 대하여 알아보았습니다. 이번 포스팅에서는 최소 신장 트리를 구현하는 또 다른 알고리즘인 Prim 알고리즘에 대해 알아보도록 하겠습니다.
Prim 알고리즘은 Union-Find 와 같은 알고리즘을 몰라도 구현할 수 있습니다. 하지만 구현이 Kruskal 알고리즘에 비해 복잡합니다.
개념
Prim 알고리즘은 다음과 같은 방법으로 동작을 수행합니다.
- 임의의 정점을 선택하여 최소 신장 트리에 추가합니다.
- 최소 신장 트리에 포함된 정점과 연결된 정점들 중에서 아직 최소 신장 트리에 포함되지 않고 간선의 가중치가 가장 작은 정점을 최소 신장 트리에 추가합니다.
- Kruskal 알고리즘과 마찬가지로 간선이 V - 1개 선택될 때까지 다음의 동작을 반복 수행합니다.
Prim 알고리즘을 이용하여 최소 신장 트리를 만들어 보겠습니다.

먼저 정점을 하나 선택합니다. 임의의 정점을 선택해도 상관없지만 시작 정점을 1로 선택하여 알고리즘을 수행하겠습니다.

현재 최소 신장 트리에 포함된 정점과 최소 신장 트리에 포함되지 않은 정점을 연결하는 간선은 1과 2를 연결하는 간선과 1과 3을 연결하는 간선 총 2개가 존재합니다.
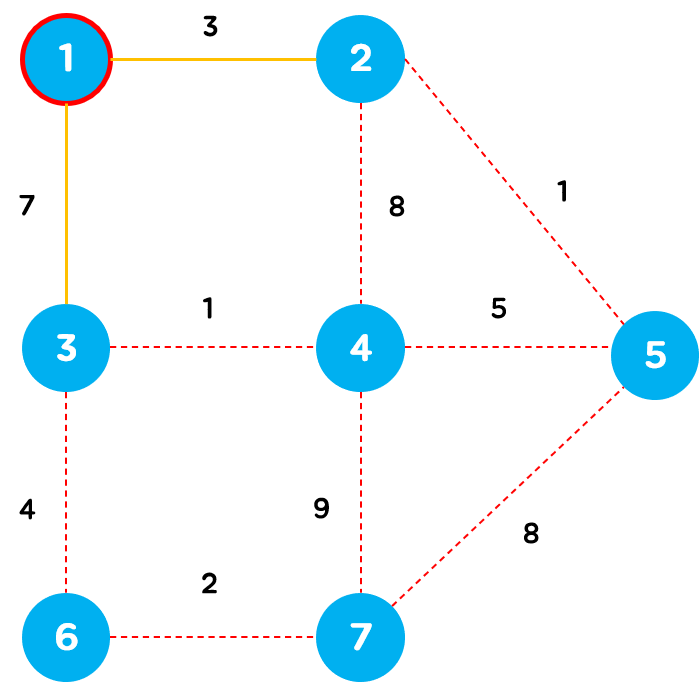
간선의 가중치가 더 적은 1과 2를 연결하는 간선을 선택하여 해당 간선과 정점을 최소 신장 트리에 추가합니다.

현재 최소 신장 트리에 포함된 정점은 1과 2이고, 최소 신장 트리에 포함된 정점과 최소 신장트리에 포함되지 않은 정점을 연결하는 간선은 1과 3을 연결하는 간선, 2와 4를 연결하는 간선, 2와 5를 연결하는 간선으로 총 3개가 존재합니다.

이 때 가중치가 가장 작은 2와 5를 연결하는 간선과 정점을 최소 신장 트리에 추가합니다.

위와 같은 방법을 으로 최소 신장 트리에 속한 간선의 개수가 총 V - 1개가 될 때까지 반복하면 최소 신장 트리를 만들 수 있습니다.

위와 같은 방법으로 Prim 알고리즘을 구현하려면 총 V - 1번을 반복하며 현재 최소 신장 트리에 포함된 정점과 그렇지 않은 정점을 연결하는 모든 간선을 탐색하고 이들 중에서 최소인 가중치를 갖는 간선틀 선택하는 방식으로 구현해야 합니다.
하지만 이 방법은 약 O(V2) 의 시간복잡도를 가지는 비효율적인 알고리즘입니다.
그렇다면 어떻게 알고리즘을 보다 효율적으로 개선할 수 있을까요?
효율적인 Prim 알고리즘의 구현을 위해서는 Heap 이라는 자료구조가 필요합니다. Heap은 원소의 삽입, 삭제와 원소의 최대값과 최소값을 탐색하는데 O(log N)의 시간복잡도로 수행할 수 있는 자료구조 입니다.
Heap 이라는 자료구조에 간선들을 넣어두면 매 순간마다 최소 신장 트리에 포함된 정점과 최소 신장 트리에 포함되지 않은 정점들을 연결하는 간선들을 모두 탐색하지 않고도 최소 가중치를 갖는 간선을 효율적으로 알아낼 수 있습니다.
개선된 Prim 알고리즘은 다음과 같은 방법으로 수행됩니다.
- 임의의 정점을 선택해 최소 신장 트리에 추가하고 해당 정점과 연결된 모든 간선을 Heap에 추가합니다.
- Heap에서 가중치가 가장 작은 간선을 꺼냅니다.
- 만약 해당 간선이 최소 신장 트리에 포함된 두 정점을 연결한다면 Heap에서 다른 간선을 꺼냅니다.
- 해당 간선이 최소 신장 트리에 포함된 정점과 포함되지 않은 정점을 연결한다면 우선 해당 간선과 정점을 최소 신장 트리에 추가합니다. 그리고 추가한 정점과 최소 신장 트리에 포함되지 않는 정점을 연결하는 모든 간선을 Heap에 추가합니다.
- 최소 신장 트리에 V - 1개의 간선이 추가될 때까지 위의 동작을 반복합니다.
위의 알고리즘의 수행과정을 그림을 통해 확인해보도록 하겠습니다.

임의의 정점 1을 선택하여 최소 신장 트리에 추가하고, 최소 신장 트리에 포함된 정점 1과 최소 신장 트리에 포함되지 않고 해당 정점과 연결되지 않은 간선들을 모두 Heap에 추가합니다.
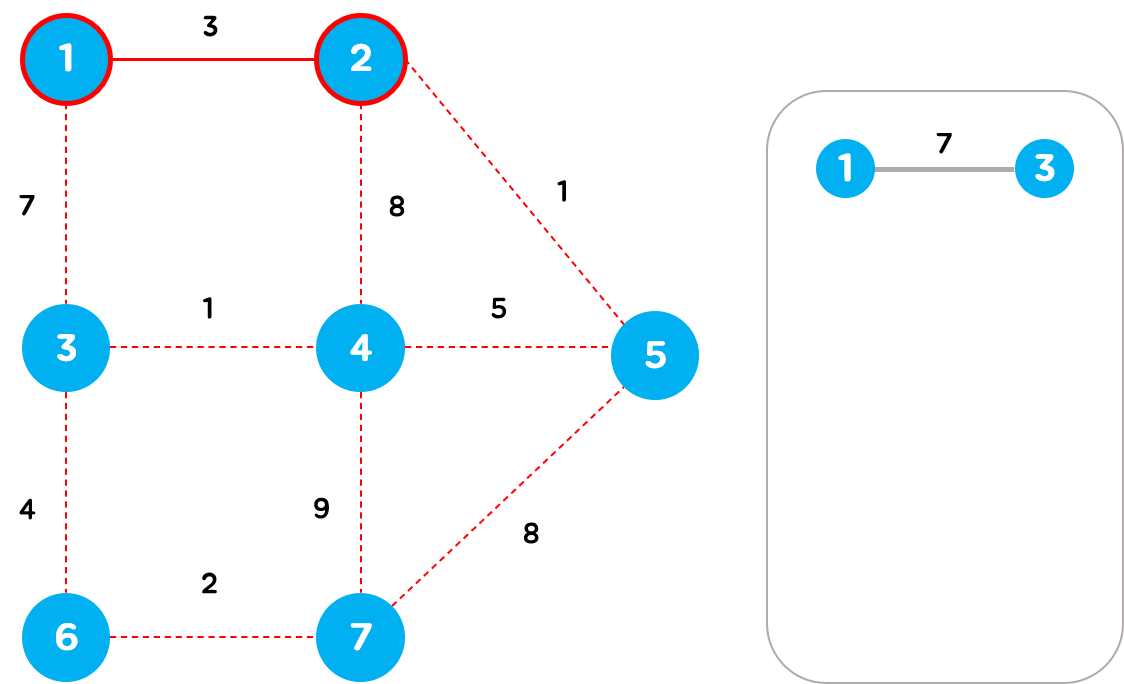
Heap에서 가중치가 가장 작은 간선인 정점 1과 2를 연결하는 가중치가 3인 간선을 꺼내서 최소 신장 트리에 추가합니다. 위와 같은 과정을 반복하면 다음과 같은 최소 신장 그래프가 완성됩니다.
위의 알고리즘 대로 최소 신장 트리를 구현할 경우 각 간선은 Heap에 최대 1번씩 들어가고 삭제됨을 알 수 있습니다.
Heap 삽입과 삭제는 각각 O(log E)의 시간복잡도를 가지게 되므로
개선된 Prim 알고리즘의 시간복잡도는 O(Vlog E)가 됩니다.
구현
코드를 통해 Prim 알고리즘을 구현해 보도록 하겠습니다. Prim 알고리즘을 어떻게 응용하고 문제에 따라 많은 구현방법이 있겠지만 위의 Heap을 이용한 구현 방법으로 구현해보도록 하겠습니다.
// 인접 리스트를 구현하기 위한 객체를 생성합니다.
static class Node{
int v, cost;
Pair(int v, int cost){
this.v = v;
this.cost = cost;
}
}
// 간선 정보를 저장하기 위한 객체를 생성합니다.
static class Edge{
int u, v, cost;
Edge(int u, int v, int cost){
this.u = u;
this.v = v;
this.cost = cost;
}
@Override
public int compareTo(Edge e) {
// TODO Auto-generated method stub
return this.cost - e.cost;
}
}
public static void main(String[] args) {
...
// 인접리스트를 초기화 합니다 정점을 1부터 시작하기 때문에 크기를 v + 1로
// 설정하였습니다.
List<Pair>[] graph = new List[v+1];
for(int i = 1; i <= n; i++){
graph[i] = new ArrayList<>();
}
PriorityQueue<Edge> pq = new PriorityQueue<>();
// 처음 임의의 정점 1에서 연결된 모든 간선 정보를 Heap에 저장합니다.
for(int i = 0; i<graph[1].size(); i++){
pq.add(new Node(1, graph[1].get(i).v, graph[1].get(i).cost));
}
visit[1] = true;
int edge = 0;
while(!pq.isEmpty()){
Edge e = pq.poll();
// 현재 최소 신장 트리를 구성하는 정점에서 연결된 간선들 중
// 최소 신장 트리에 포함되지 않은 정점을 찾습니다.
if(visit[e.v]) continue;
// 정점을 찾은 경우 방문표시를 함으로써 최소 신장 트리에 포함 시켜줍니다.
visit[e.v] = true;
edge += 1;
// 간선의 개수가 v - 1개일 경우 최소 신장 트리가 만들어진 것이므로
// 탐색을 종료합니다.
if(edge == v - 1) break;
// 해당 정점에서 최소 신장 트리에 포함되지 않은 연결된 모든 간선 정보를
// heap에 저장합니다.
for(int i = 0; i<graph[e.v].size(); i++){
if(!visit[graph[e.v].get(i).v]);
pq.add(new Edge(e.v, graph[e.v].get(i).v, graph[e.v].get(i).cost));
}
}
}비교
두 개의 포스팅에 걸쳐서 최소 신장 트리를 만드는 알고리즘인 Kruskal 알고리즘과 Prim 알고리즘에 대해 알아보았습니다. 각각의 알고리즘을 간략하게 정리하면, Kruskal 알고리즘은 가중치가 최소인 간선을 하나씩 선택해 나아가면서 최소 신장 트리를 만들어나가고 Prim 알고리즘은 하나의 정점에서 연결된 간선들 중에 하나씩 선택해 나아가면서 최소 신장 트리를 구현합니다.
그럼 과연 언제 어떤 경우에 어떠한 알고리즘을 사용하는것이 효과적일까요?
무조건적인 지표는 아니지만 대체적으로 간선이 많은 경우는 Prim 알고리즘이 간선이 적은 경우는 Kruskal 알고리즘이 최소 신장 트리를 구현할 때 효과적으로 동작합니다.
Kruskal 알고리즘의 시간복잡도는 O(Elog E)이고 Prim 알고리즘의 시간복잡도는 최악의 경우 O(V2) 최선의 경우 O(Vlog E) 가됩니다.
그래프에 약 1,000개의 정점이 있다고 가정했을 때, 완전 그래프에서는 총 V(V+1) / 2 개의 간선이 만들어 질 수 있으며 이는 500,500개에 해당합니다. 이 때 시간복잡도를 계산해보면
O(V2) ≒ 10002 = 1,000,000 < O(Elog E) ≒ (500,500)log(500,500) ≒ 2.852551 × 106 에 해당됩니다. 이는 정점의 개수가 많아짐에 따라 간선의 개수가 같이 증가하게 되면 더 차이가 벌어지게 됩니다.
완전 그래프와 같이 간선의 개수가 많은 경우에는 Prim 알고리즘을, 상대적으로 간선의 개수가 적은 경우에는 Kruskal 알고리즘을 사용하면 효과적으로 최소 신장 트리를 구현할 수 있습니다.
'알고리즘 > 이론' 카테고리의 다른 글
| [알고리즘] 그래프 (5) - 다익스트라 알고리즘 (Dijkstra's Algorithm) (0) | 2020.04.10 |
|---|---|
| [알고리즘] 정렬(6) - 퀵 정렬(Quick Sort) (0) | 2020.04.10 |
| [알고리즘] 정렬(5) - 병합 정렬(Merge Sort) (0) | 2020.04.09 |
| [알고리즘] 그래프(3) - 최소신장트리 MST (1) (0) | 2020.04.09 |
| [알고리즘] 정렬(4) - 계수 정렬(Counting Sort) (0) | 2020.04.08 |